2022年,随着OpenAI推出ChatGPT,“生成式人工智能”开始进入公众视线并逐渐受到广泛关注。这种新型的AI不仅可以生成文本,还可以创建图像和视频等多类型的内容,几乎堪称“万能”。进入2023年,生成式AI的发展势头更为猛烈。
相较于过往的人工智能时代,机器学习只是在模仿人类认知世界的方式,生成式AI的出现则预示着人工智能已进入一个新纪元。在此新纪元中,机器不仅可模仿人类,更开始替代人类去创新,给社会生产力发展带来巨大推动力。
一、 基本概念
自从20世纪50年代图灵测试提出以来,人们就一直在探索让机器处理语言的可能性。机器只有理解了人类的语言,才能通过语言来学习人类文明的知识,并与人类进行有效的沟通。
语言模型是处理语言文字(或者符号体系)的AI模型,它能识别人类语言中的规律,并根据给定的提示,自动生成符合这些规律的内容。近年来,研究人员在大规模语料库上训练得到的语言模型在解决各类自然语言处理任务上展现出了强大的能力。这种模型甚至产生了一个有趣的现象:即当模型的参数规模超过一定水平时,它的性能会显著提升,并且会出现一些在小模型中不存在的新能力,比如上下文学习。为了与基于统计或神经网络的语言模型区分,这种模型被称为“大型语言模型”(Large Language Model,简称LLM)。
尽管大语言模型目前没有正式的定义,但它通常指由具有许多参数(通常数十亿个权重或更多)的人工神经网络组成语言模型,它通过处理和理解自然语言文本数据来进行预测和生成新的文本。简单地说,它就像一个掌握了多门语言的人,不仅可以理解和解释已有的文本信息,还可以根据给定的上下文环境猜测一个句子或段落接下来可能出现的内容,甚至可以自己想出新的词汇或概念。
生成式AI与大语言模型关系
图 1生成式AI与大语言模型关系
生成式AI(Generative AI 或 AIGC)是一种借助深度学习技术,基于大模型(包括但不限于语言模型)创造全新内容和想法的先进技术,可以生成全新的数字视频、图像、文本、音频或代码等内容。图像生成领域的应用包括DALL·E-2、Stable Diffusion等,自然语言处理领域的应用包括ChatGPT,代码生成领域的应用包括Github Copilot等,多媒体生成领域的应用包括MusicLM、MusicGen等。
使用大语言模型的生成式AI,可以根据输入的文本或关键词,自动生成连贯且有意义的文本,可以广泛应用在文本摘要、机器翻译、对话系统、文本生成和知识图谱等领域。
总而言之,大语言模型与生成式AI密切相关,前者为后者提供了强大的自然语言处理能力,并使得生成式AI在各种任务中表现出色。
二、 全球大语言模型总览
目前,全球领先的生成式AI大语言模型主要有OpenAI的GPT-3、GPT-4,Google 的PaLM 2、T5,Facebook 的Galactica 、LLaMA 等,这些模型都具有超大规模的参数量(从几十亿到几千亿)、支持多语言交互。基于大语言模型,部分开发机构已经构建面向消费者及行业用户的生成式AI应用,典型应用包括ChatGPT、Bard、Claude。
在中国,诸多研究机构和企业也在积极开发生成式AI大语言模型,包括北京智源人工智能研究院的悟道系列、百度的ERNIE系列、科大讯飞的星火认知大模型以及清华大学的CPM系列等。
表 1 国内外主要大语言模型
模型名称 | 开发机构 | 模型大小(训练参数) | 发布时间 | 面向消费者的应用 |
国外 |
PaLM 2 | Google | 3400 亿 | 2023/05/10 | Bard |
Med-PaLM 2 | Google | 未知,基于PaLM 2的医疗领域语言模型 | 2023/03 | 暂无 |
GPT-4 | OpenAI | 未公开,推测为17600亿 | 2023/03/14 | ChatGPT |
LLaMA | Facebook | 650亿 | 2023/02/24 | 暂无 |
AnthropicLM v4-s3 | Anthropic | 520亿 | 2023/01 | Claude |
GPT-3 | OpenAI | 1750亿 | 2020/05/28 | ChatGPT |
国内 |
WinGPT 2.0 | 卫宁健康 | 130亿,医疗领域语言模型 | 2023/07 | 暂无 |
悟道3.0 | 北京智源 | 未公开,2.0版本为17500亿 | 2023/06/10 | 暂无 |
HuatuoGPT | 香港中文大学(深圳)、深圳市大数据研究院所 | 130亿,医疗领域语言模型 | 2023/5/25 | 华佗GPT |
MedGPT | 医联 | 1000亿 | 2023/5/25 | 暂无 |
星火认知大模型 V1.5 | 讯飞 | 未知 | 2023/06/09 | 星火 |
CPM-Bee | 清华大学 | 100亿 | 2023/05/27 | 暂无 |
ERNIE 3.0 Titan | 百度 | 2600亿 | 2021/12 | 文心一言 |
尽管大语言模型和生成式AI仍处于早期发展阶段,但其在医疗健康行业中的应用正在逐渐增多,潜力和影响力也在不断扩大。在临床场景,能够分析医学文献和患者信息,协助识别疾病,预测疾病风险,并定制个性化治疗计划;在患者服务场景中,可充当健康咨询师的角色,推动患者沟通,并对健康生活方式的选择提供指导;在临床研究场景中,有助于解析疾病机理,并加快新药物的开发;在管理场景中,可用于自动化处理病历管理和保险索赔等行政任务。
Google推出的医疗行业定制模型 Med-PaLM 2 ,可以从各种密集的医学文本中总结见解并回答相关问题,是第一个在美国医疗执照考试 (USMLE) 数据集MedQA 上达到“专家”应试者水平表现的大语言模型,准确率达到 85% 以上。香港中文大学(深圳)和深圳市大数据研究院发布医疗大模型 ——HuatuoGPT(华佗GPT),使语言模型在在线咨询问诊场景中,具备像医生一样的诊断能力和提供有用信息的能力,同时保持对用户流畅的交互和内容的丰富性,对话更加“丝滑”。卫宁健康自主研发的专注医疗领域的大型语言模型 - WiNGPT,支撑七大基础任务(问答、多轮对话、信息提取、标准化、文本相似度计算、摘要、分类、生成)以及超过20个子任务。WiNGPT将以Co-Pilot诊断辅助模式融合到数字化医疗系统WiNEX中,提供全景式、沉浸式的智能应用,如在健康体检场景中,WiNGPT可以对体检记录进行剖析,自动生成总体检查报告和健康指导建议;在影像检查场景中,WiNGPT可以解析患者的多次检查影像及相关报告,自动产出疾病进展分析和预测。
三、 生成式AI市场及投融资现状
据《福布斯》报道,全球人工智能投资从 2015 年的 1275 万美元飙升至 2021 年的 935 亿美元。进入2023年,尽管全球风险投资势头低迷,但生成式AI的蓬勃发展吸引了大量投资。市场分析公司PitchBook Data数据显示,仅在2023年第一季度,生成式AI初创企业的融资规模就达到了2022年全年投资资金的四倍, 2023年底将达到426亿美元,到2026年将达到981亿美元。另外,IDC预计,2026年中国人工智能市场总规模预计将超264.4亿美元。
科技巨头也在生成式AI领域展开竞争、进行大规模投资,并对初创公司进行积极收购或建立合作关系,以便跟上AI新时代的步伐。微软于2023年1月向OpenAI投资了100亿美元;谷歌于2023年2月向Anthropic(Claude的开发商)投资了约3亿美元;大数据公司Databricks在2023年6月以13亿美元收购了生成式AI初创公司MosaicML。
随着生成式AI大语言模型的训练和使用成本的迅速降低,众多AI研究人员从学术界转向初创公司,投入到模型和产品的开发中,受到了大量投资机构和资本的青睐。Stability(Stable Diffusion的开发商)于2022年10月完成了1亿美元的融资,百川智能于2023年获得了5000万美元的天使轮融资,光年之外于2023年获得了3亿美元的融资。
值得注意的是,垂直行业大模型市场正在成为一个重要的机会所在,Google、Facebook以及国内外的医疗信息化厂商都在积极开展面向医疗行业的专用大语言模型的训练。
四、 大语言模型技术机制与流派
大语言模型的强大力量在很大程度上归功于它们使用的Transformer模型架构和注意力机制,这种架构和机制使得这些模型能够理解并生成复杂的文本内容。值得一提的是,这些大语言模型在训练时,会处理数以百亿计的语料库,包括各种各样的书籍、文章、网站和其他形式的文本。这样,模型就能够学习到各种语言模式,包括语法、词汇、习语,和各种真实事件(事实型知识)和常识性知识。而且,这些模型都经过了精细的训练和调整,以确保它们在实际应用中能够生成准确、连贯、自然的文本。
Transformer模型由“编码器(Encoder)”和“解码器(Decoder)”两部分构成。编码器部分主要负责理解输入的文本,并为每个输入构建相应的语义表示。解码器部分则负责产生输出,它利用编码器输出的语义表示和其他输入信息来生成目标输出序列。根据Transformer模型中编码器和解码器模块的注意力机制模式不同,目前的大语言模型主要可以划分为三类:编码器架构(Encoder-Only)、解码器架构(Decoder-Only)和编码器-解码器架构(Encoder-Decoder)。
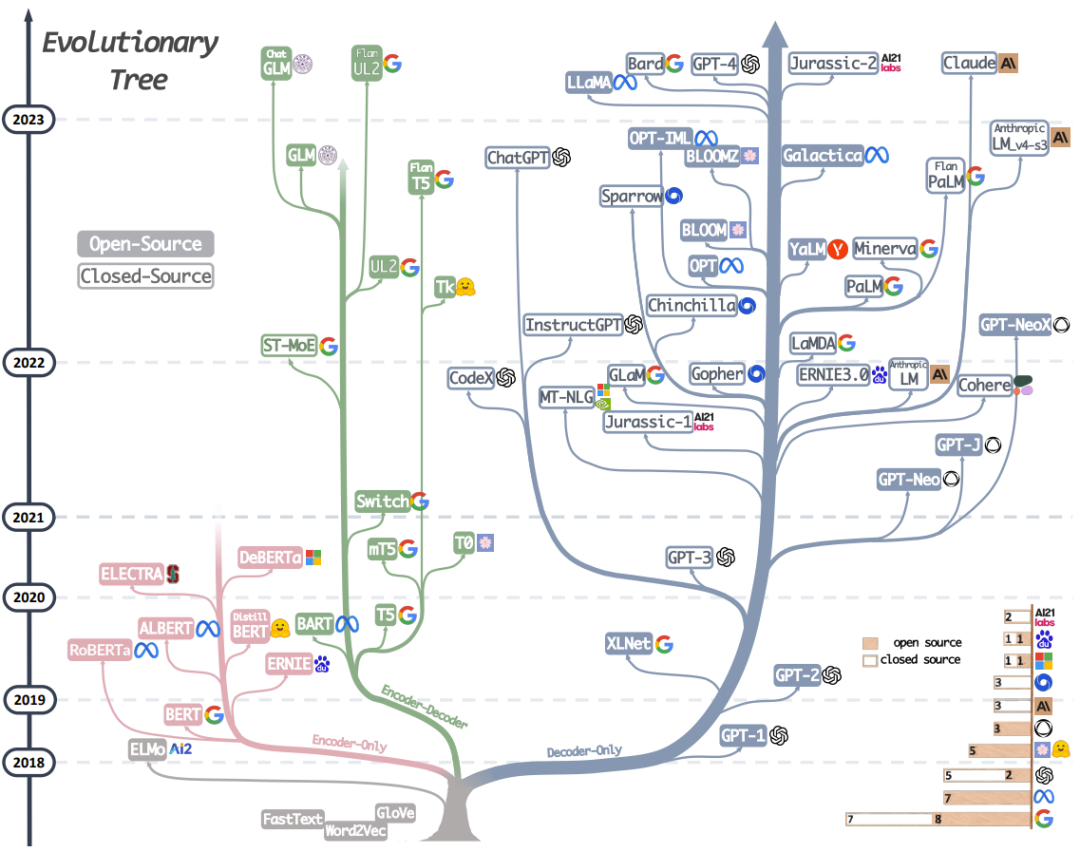
图 2 大语言模型演化树
编码器架构:以Google BERT (Bidirectional Encoder Representations from Transformers)为代表,它在训练时考虑了上下文的双向信息,因此能够更好地理解语言的语义。适用于文本分类、命名实体识别等场景。
解码器架构:以OpenAI GPT (Generative Pre-training Transformer) 为代表,它在训练时只考虑上下文的单向信息,但是在生成文本时却有很好的连贯性。适用于文本生成、对话等场景。
编码器-解码器架构:以Google T5 (Text-to-Text Transfer Transformer) 为代表,这种架构结合了编码器和解码器的优点,通常用于序列到序列的任务。适用于机器翻译、文本摘要等场景。缺点是模型的复杂度较高,需要更多的计算资源和训练时间。
今年以来,对大语言模型的高效参数微调以及特定领域数据的训练,使得其计算效率和数据利用效率得到了显著提升,在各行业领域的应用中也取得了广泛的好评。2023年3月发布的PaLM-E模型更是揭示了大语言模型的发展趋势,即通过视觉、多模态和多任务训练来拓展其能力,预示着更多突破想象的"类人脑"人工智能应用的崭新可能性。
在医疗这样一个数据密集型的行业,大语言模型和生成式AI已经展现出不可忽视的前景。我们深信,随着这些先进技术与医疗场景、流程的深度融合,我们将迈入一个由AI驱动的智慧医疗新时代。


{kind=link}